Lecture 04 Database Storage Part 2
tuple-oriented storage
上节课所描述的 大致称为 tuple-oriented storage 基于元组的存储方案
核心在于:
如果我获得了一个tuple 我需要将其放置在某处
- check page directory to find a page with a free slot
- retrieve the page from disk( if not in memory)
- check slot array to find empty space in page that will fit.
update a tuple:
- check page directory to find location of page
- retrieve the page from disk (if not in memory)
- find offset in page using slot array
如果新的更新元组的大小与现有元组大小相同 那么我们只需要覆盖现有元组就可以
如果不可以 或许需要寻找另一页来容纳 或者在当前页(如果当前页有空间的话)
what problem this?
- 如果只是读取 It' ok. 但是如果开始更新数据 写入 插入 更新 删除 最终可能导致业内碎片化 换句话说就是我有未充分利用的页 这意味着我有一小块空闲空间 无法容纳新的元组
存在大量无用的磁盘空间
更新新元组 如果不存在于内存中 必须访问磁盘并将其读取出来
我必须获取整个页并大量引入数据 -- 其中包含好多我不需要更新的数据
随机磁盘IO
如果一次更新20个tuple 并且在20个不同的page上 就需要读取20个独立的页面
问题的核心在于 我们假定 无法在slot page中原地更新
我们刚刚讨论的问题 都将通过日志结构的存储方案得到解决
today's agenda
- Log-Structured Storage
- Index-Organized Storage
Data Representation
在堆文件和页面架构之外 日志结构存储可能是数据系统中人们采用的第二种常见的方案
然后我们会讨论另一种方法 并非严格意义上的日志结构 而是两者的融合 -- 索引组织存储 MySQL SQLite
然后学习如何在元组中实际表示属性的数据
Log-Structured Storage
日志存储结构 - 90年代中期提出 在教科书中 被称为 log-Structured merge treees
日志结构存储的基本思想是:不存储单独的元组 而是维护这些元组变更的日志记录
可以想象成一种键值存储系统 如放置和删除 会得到一个键值对
键对应某个元组标识符
我们将按到达顺序将新的日志条目附加到内存缓冲区中
某个时刻 缓冲区被填满 我们就写入disk
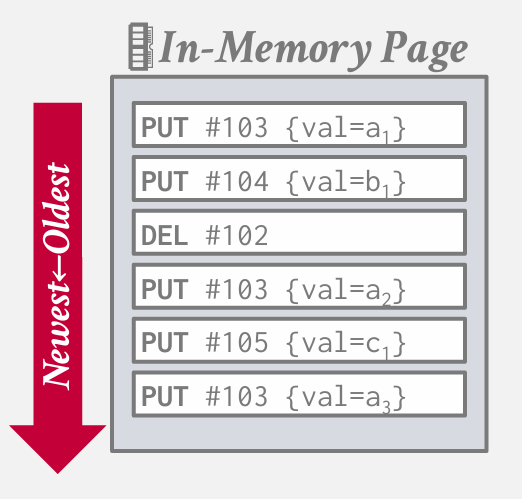
满了之后是将整个page直接转移到disk中 --- 写入就意味着不可变了
因此写入操作会变得很快 只需要在最后增加log
但是读取操作 会变慢 --- 首先检查内存中的page 从末尾开始逆序检查 这并不高效 解决这一问题的方法 就是日志结构合并树 log-Structured merge tree
核心就是对每一个记录ID 会告知你在内存缓冲区页中的具体位置
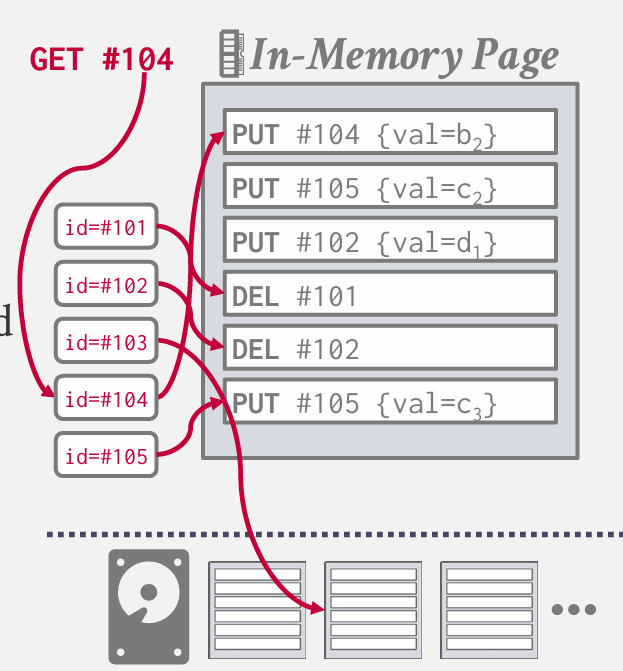
如果需要104 就去索引中查找 这通常是一个b+数 也可能是 字典树 有些系统则采用跳表(skip lists)
在日志结构的数据库存储系统中 他们会定期运行一些后台任务 这些任务将压缩页面 减少冗余操作
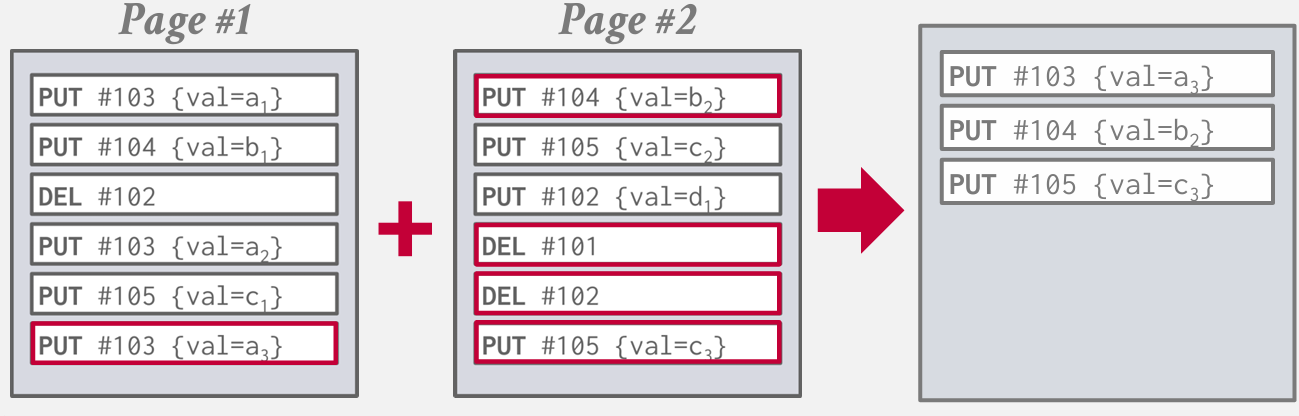
更新之后 就无法看出哪一条比哪一条更早了 因为可能进行键值对排序
这种表叫做Sorted String Tables (SSTables)
如果已经排序 那么查找的时候 只需要构建一个索引或者过滤器 直接跳转到要查询的记录就可以了 就不必在整个文件中查询了
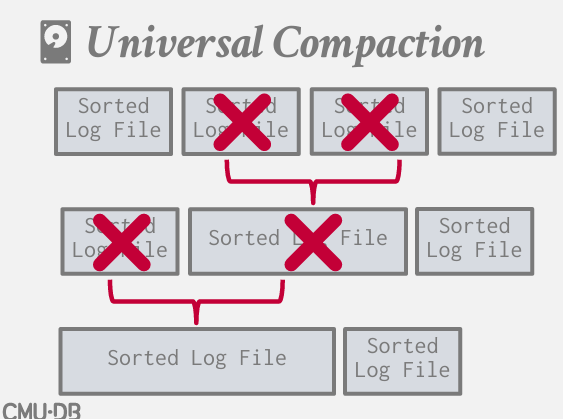
压缩主要有两种方式
- universal compaction --- 全局压缩
- level compaction
最简单的形式 成为全局压缩 -- 将磁盘上相邻的已排序的日志文件合并
我感觉有点像 归并排序?呃呃就是归并排序哈哈哈

另一种压缩叫做level compaction 层级压缩
!!levelDB中level的由来
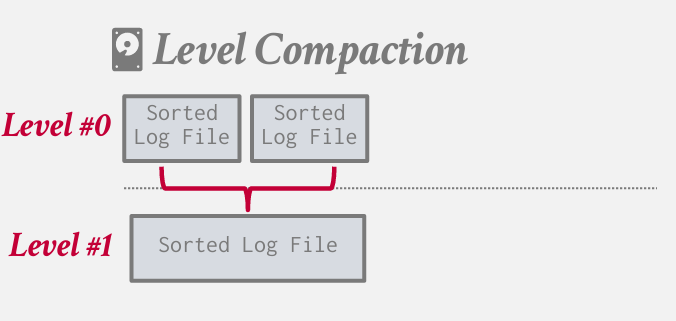
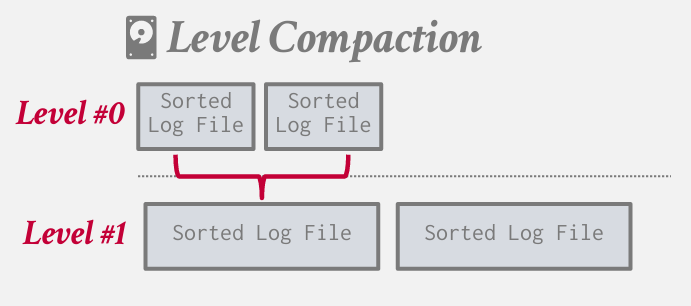
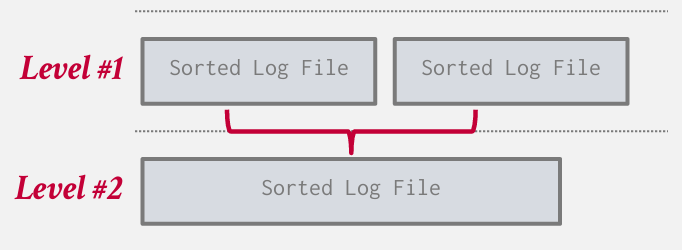
每一层都是固定的大小 一层比一层大
RocksDB就是这样的 RocksDB是facebook对于LevelDB(Google的)的分支
我写区块链的时候好像就是用的LevelDB
现在RocksDB已经成为许多数据库供应商默认的选择 人们构建数据库会将其最为底层存储管理器
日志结构的数据库 读取满 压缩需要成本 压缩的时候需要重新读入内存 再写回磁盘 叫做write-amplification(写入放大)
Index-organized storage
一种替代方案是 --- 自动保持元组按照索引进行排序
这就是所谓的 index organized storage or index organized tables
可以是树形结构 也可能是 哈希表 这里假设是树形结构
底部的叶子结点不是存的位置 而是数据本身
tuples are typically sorted in page based on key
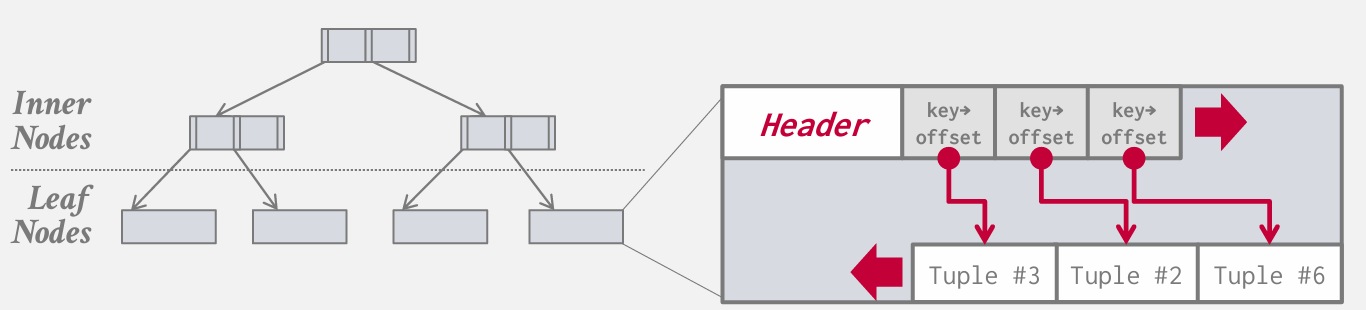
这是一个粗略的b+树示意图 后面会详细介绍 内部节点和叶节点不同 内部节点就相当于指示牌
叶节点本身非常类似于 之前的slot page
区别在于 在页内 基于键值对进行排序 而不是仅仅根据在slot array中找到空闲位置并随机放入
查找: 遍历索引 到达叶节点 进入page 然后对键值对进行二分 得到偏移量 然后找到tuple
这就是MySQL的InnoDB引擎所得到的结果
SQLite也是这样 上节课有一个rowID rowID就是索引内部进行查找的关键字 真正的主键——逻辑主键 我们会建立一个独立的索引 该索引将主键通过地址映射到行ID
仍然不可避免碎片化IO和随机IO —— B+树至少要半满 会存在一批空白的叶节点 而且在page内部 也会可能有没法用的空间
对于随机IO 只需要更新树的一部分 所以具有一定的优势
tuple storage
我们提到一个tuple 实际包含了哪些内容?
tuple就是一串字节序列 比如a列是32bit 的整数 b列是 64bit的整数
database system做的就是解释这些字节是什么
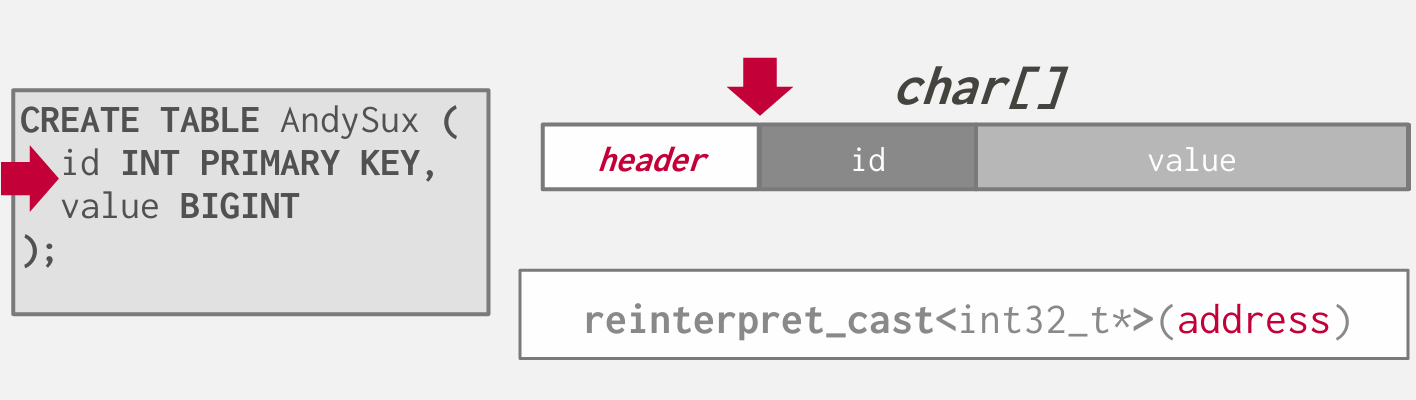
头部的大小对于每个tuple都是相同的我们知道怎么跳过它
然后做一些简单的算数运算 来找到要找的属性的起始位置
存在对齐原则 就是之前学的那个对齐原则!
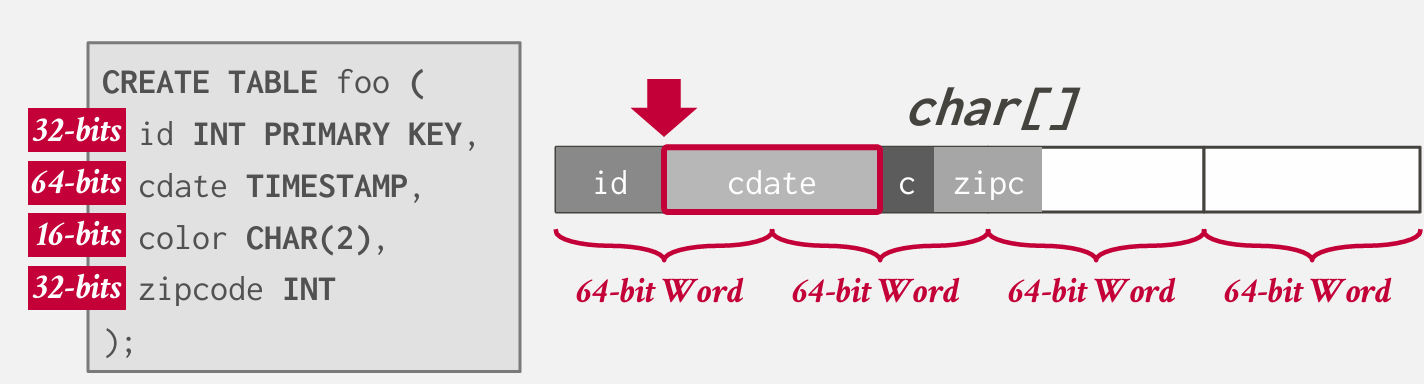
显然不行
cdate横跨了两个字长 会发生什么
x86 Intel会自己给你做好这一切 他会做额外的工作再取一次 但是这仍然会降低数据库的性能
而且并非所有的系统和架构都会帮你做好
在之前ARM中 会拒绝请求 ARM7也会像intel似的 做好
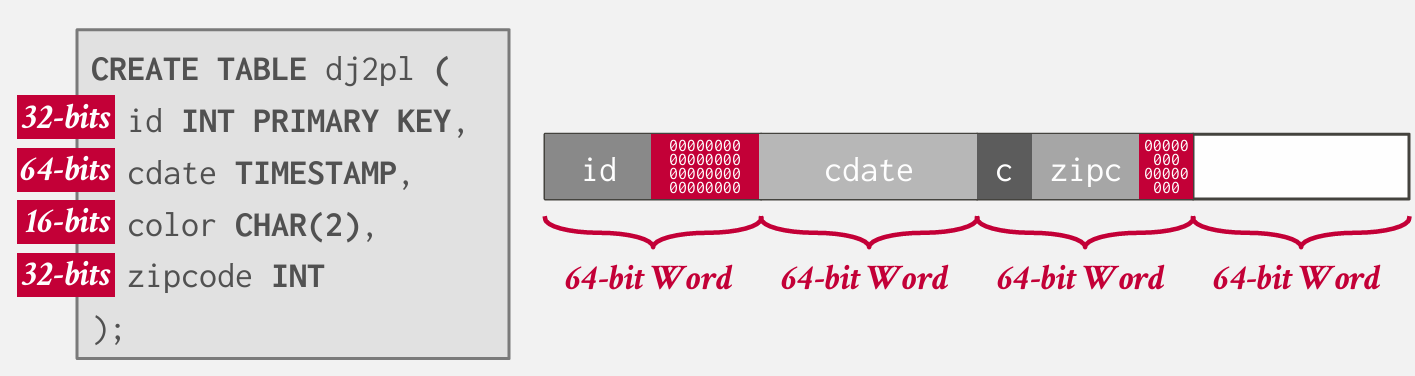
在横向填充的时候 如果下一个字段没法放到剩余的单个字中 就会填充一堆0
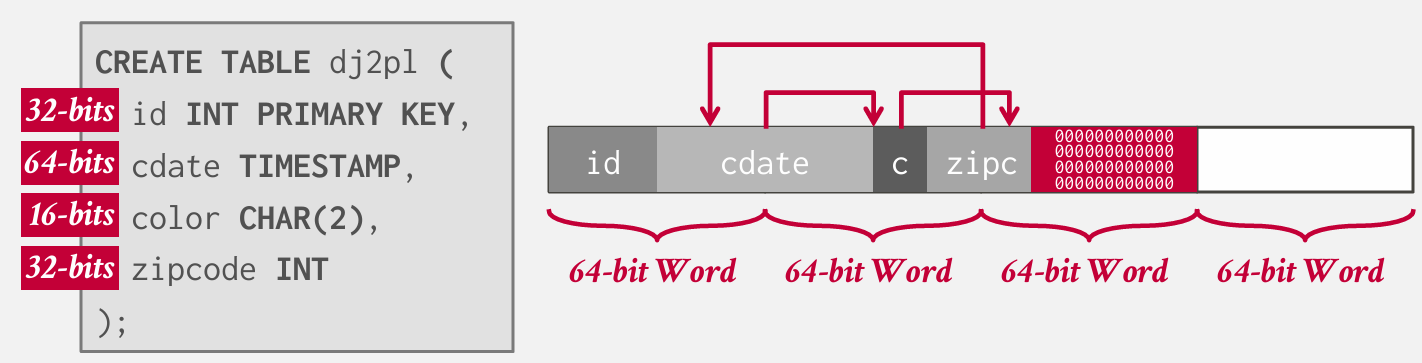

还有一种方法是重排序 但是好像大多数系统不会自动做好这个
对于varchar 如果太大 可能不是按行这么存的 而是存的是一个别的地方的指针
Postgres不会自动排序 但是会填充
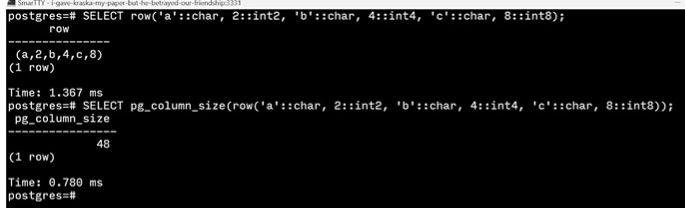
但是如果先插入int 在插入char 能压缩到44字节

data representation
integer bigint smallint tinyint 与c++分配变量 时得到的结果一样
因为硬件对于二进制补码表示整数 都有一个标准的表示方法 这是硬件所决定的 详见CSAPP
对于浮点型 严格按照IEEE的定义
但是存在定点表示 这个会根据不同系统而不同 而且与浮点型会有一定的性能差异
对于varchar varbinary, text, blob 通常会存储为带有头部的形式 该头部指示了数据的长度
如果数据过大 无法在元组的自身页面内直接存储 会有一个指针 只想包含所需属性数据的另一页面
time, date, timestamp, interval: 32/64bit integer来表示 是unix纪元的毫秒或者微秒数
存在大端法 和 小端法 (在CSAPP中和机组中都学到过) 所以从一个系统复制到一个系统会发生错乱 但是SQLite避免了这一问题 将所有的数据都存为varchars 在运行时 会根据属性中 的类型 发生转换
浮点数比定点数更快 --- 因为机器原生支持 -- 但是大规模计算 会存在误差 因为无法保证数值的准确性 CSAPP中也讲过
为了解决这一问题 数据库系统会提供固定精度的数值 数据库系统会做一些额外的操作 来确保不会遇到这些舍入误差 就像Java中的BigDecimal python中的decimal
这是Postgres做的:
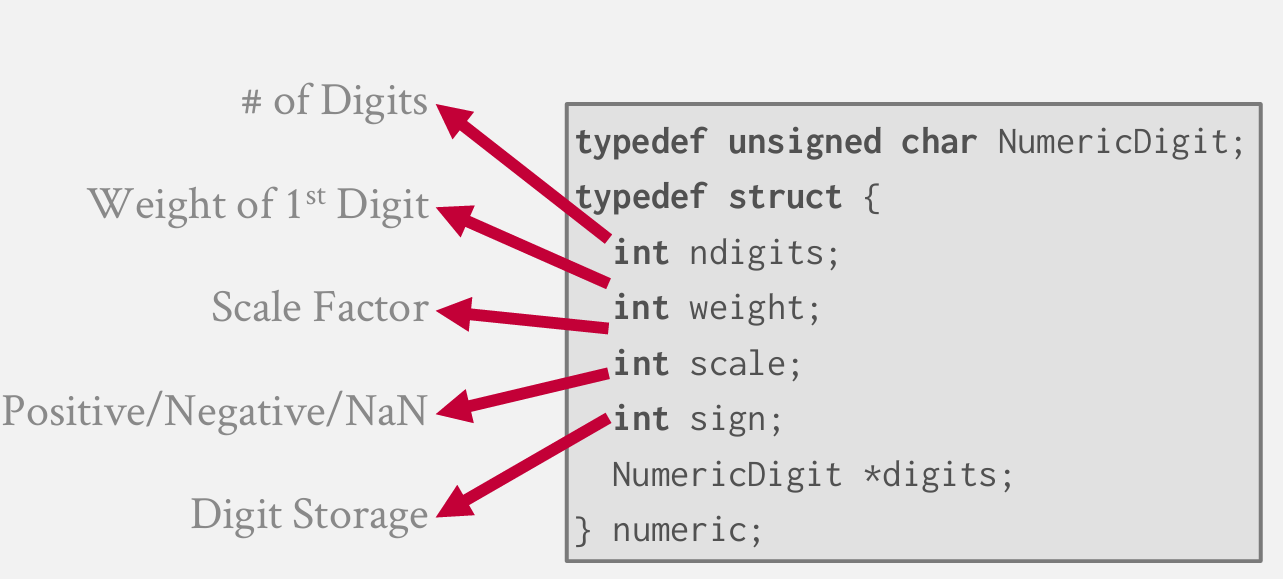
他们将数值类型标识为某种结构体
这是postgres对两个数值进行加法运算的简短示例

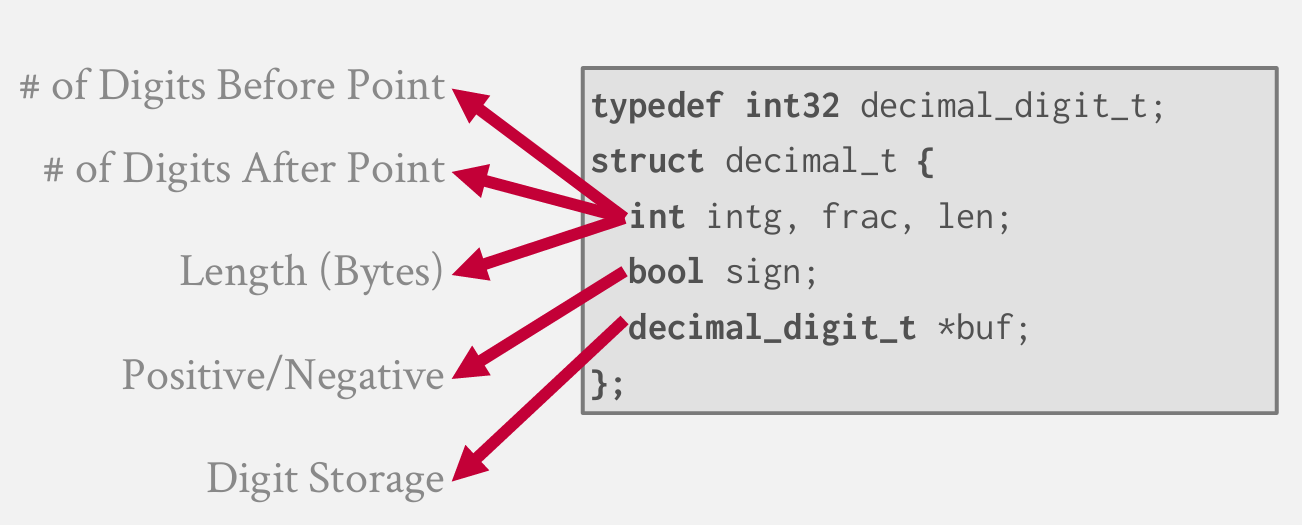
mysql中也是这样做的 他们将数字集合存储为VAR图表 将以32bit形式存储 但同样 还需要额外的元数据来记录该数值类型
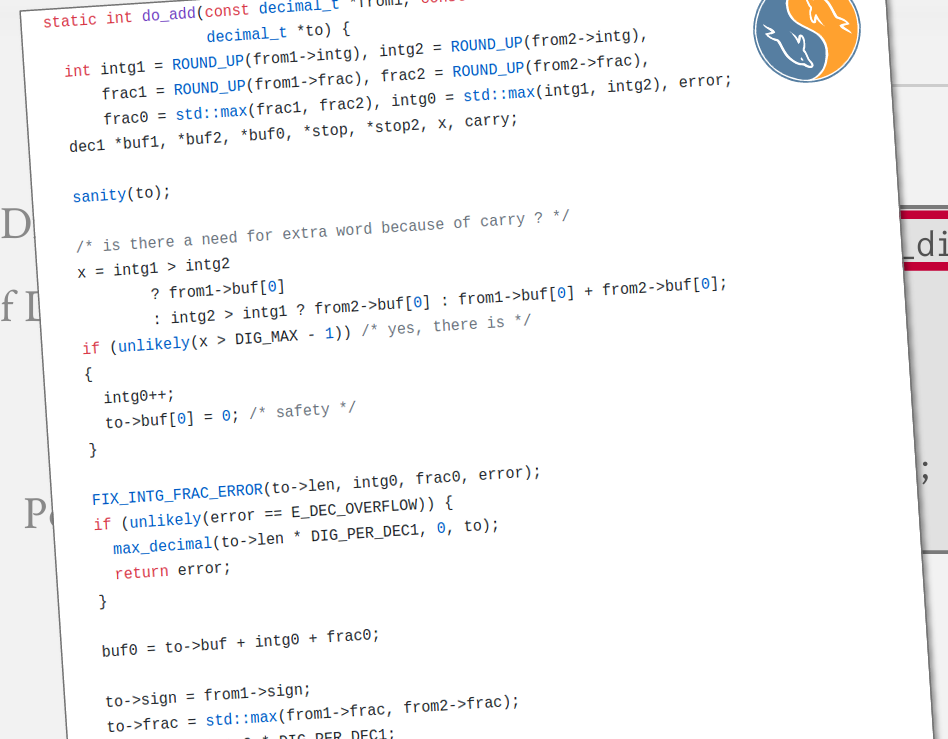
他们也有自己的实现加法运算的方法
null data type
对于空值处理 最常见的方法是,对于头部的每一个元组 都会有一个位图来记录该元组中哪些属性被设置为空值 改位图的header的大小会根据您拥有的属性数量而变化 我们可以确定哪些为空 因为我们在创表的时候给出的 --- 我们可以设置非空
较为少见的一种方法是设置特殊值 即声明在每种数据类型的取值范围内存在一个特殊值 若遇到辞职 我们认为是空
最糟糕的选择 -- 老师只见过一个系统采用过 就是对于tuple的每一个属性 设置一个小标志在前面 这种方法之所以糟糕 是因为对齐问题 32bit的整数 前面再加1bit来表示 这个东西为空 如果64bit对齐 我可能需要存储双倍大小的数据 (因为原来64bit 刚好存两个32bit的整数 现在因为一个整数需要33bit 而却又要对齐 所以需要两个64bit) 唯一真正实现的一个系统 MemSQL SingleStore的早期名称
large values
对于非常大的值 大多数数据库系统不会允许直接存储在tuple所在的页面本身 而是包含一个指针 一个record id 以及一个偏移量 这些信息回指向查找所需实际值的位置
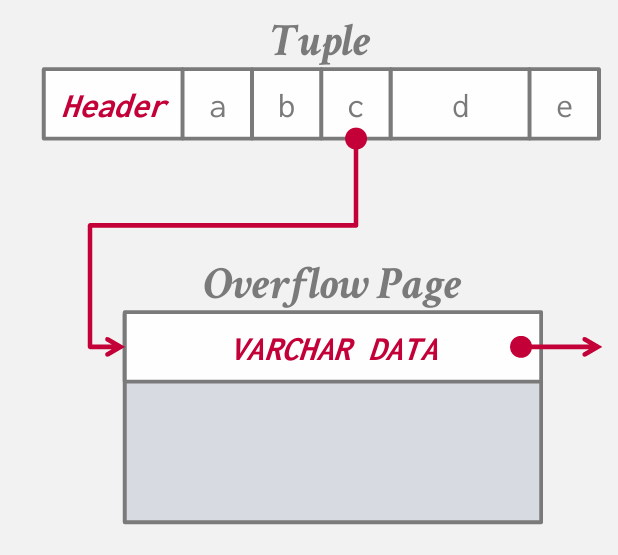
所以存在一个阙值问题 何时需要将数据放入所谓的overflow page
- 在Postgres中 他们称之为 TOAST 任何大于两千字节的属性 都会存储为单独一页
- MySQL 中 叫overflow 大于1/2 size of page
- 在SQL Server中可以设置 但是默认是 加入这个超大型属性的数据后 >size of page的时候溢出
external value storage
外部值存储
数据库系统并不会将大型数据或属性存储在它管理的页面上 而是会将这些数据写入到本地文件系统中 并在内部存储该数据的URL位置信息 当你针对该表进行查询并获取该属性时 系统会向操作系统请求该数据 然后数据会被复制到缓冲区 然后返回给你
好像只有Oracle 和 SQL Server真正实现了这一点
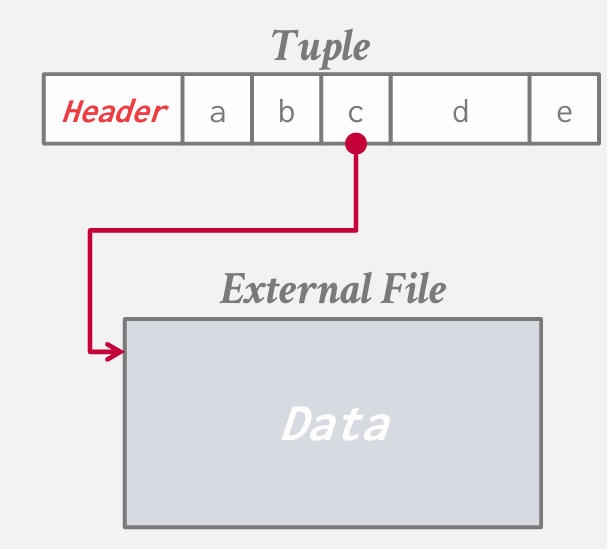
- Oracle中 成为 BFile data type
- 在SQL Server中叫 FileStream data type
但是SQLite的创建者 认为 缩略图和图片存储在数据库系统中更为合适 因为在检索这些数据时, 应用程序已经打开了数据库系统 直接从数据库系统获取缩略图会被执行一系列的fopen 和fread操作来访问磁盘上的大量文件快的多